
Suite à mon article sur les biais en machine learning et le développement responsable des produits en AI, j’ai interrogé cinq personnes qui vivent ces défis au quotidien. Data Scientist, Product Manager et responsable d’équipe, ils/elles ont en moyenne 10 ans d’expérience en intelligence artificielle dans des PME et très grandes compagnies.
Pour identifier l’origine du biais en ML, j’ai cherchais à comprendre avec mes interlocuteurs les défis propres au développement ce type de produit. Nos échanges étaient tellement riches – et ils auraient pu continuer encore longtemps, que j’ai découpé les principaux apprentissages en trois articles:
- Comment gérer un produit avec du machine learning
- Quelles sont les compétences pour développer un produit de machine learning
- Comment limiter les biais dans un produit de machine learning
Un grand merci pour leur généreuse contribution à cette réflexion:
- Philippe Bouzaglou, Director of Data Science, Gorillas
- Salma Naccache, Data Scientist
- Jérôme Pasquero, Senior Product Manager, Sama
- Philipe Beaudoin, Co-Founder & CEO, Waverly
- Mrs X (anonymat requis), Directrice de l’ingénierie de recherche, BigCorp
Boom des développements en machine learning
Aidés par un afflux massif d’argent, les développements en machine learning ont explosé ces cinq dernières années. Tous produits confondus, les startups en intelligence artificielle ont récolté 144 milliards de dollars d’investissement entre 2017 et 2021.
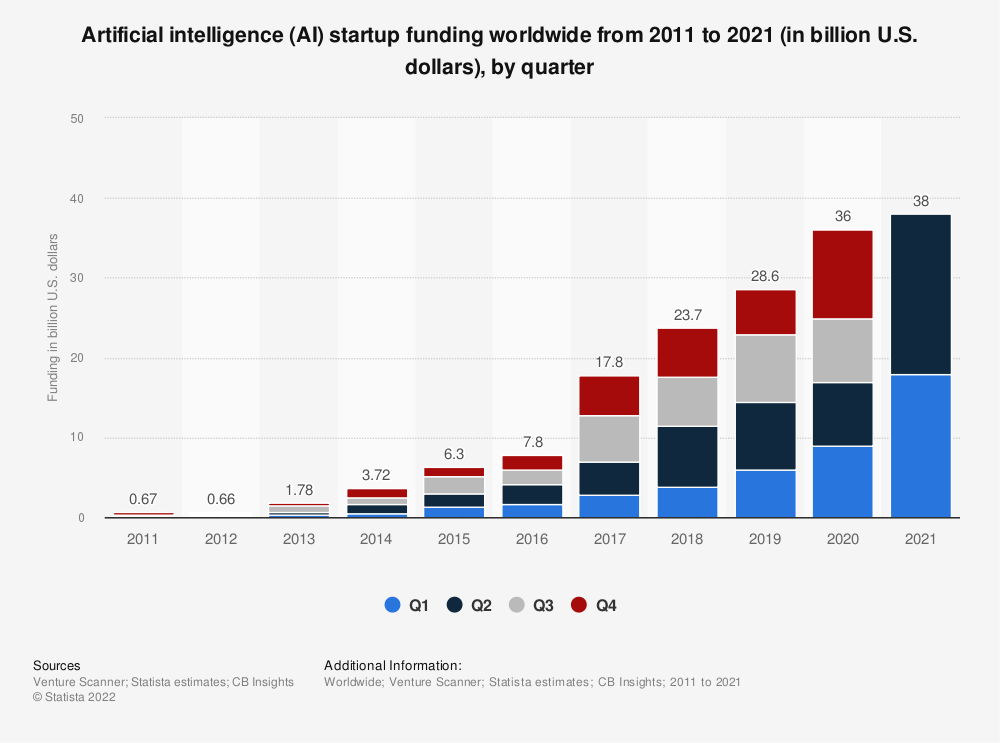
On manque encore de recul, mais on sait déjà qu’il est difficile d’appliquer exactement à un produit de machine learning tout ce qu’on a appris depuis 30 ans pour le développement logiciel traditionnel. À l’aide de mes cinq experts, j’ai donc identifié quatre points importants pour aider à bien gérer les défis spécifiques d’un produit de machine learning
- Gérer l’imprévisible
- Tester en continu
- Limiter la complexité
- Faire face au hype
- Gagner en maturité
Gérer l’imprévisible
Logiciel traditionnel vs logiciel de machine learning: la plus grande différence, c’est le côté imprévisible des résultats. Avec du machine learning, les données qui sont ajoutées en continu transforment le produit en véritable machine vivante qui n’évolue pas forcément dans le sens qu’on avait prévu.
On ne sait pas si un modèle va marcher et comment l’application va réagir.
Combien de temps et combien de données ça va prendre? Est-ce que ça va être biaisé? Est-ce que ça va être bien accueilli par les utilisateurs? Est-ce qu’ils vont y faire confiance? Est-ce qu’il y a risque de défaillance catastrophique?… Toutes ces choses-là sont beaucoup moins problématiques dans du développement software traditionnel, où on a une meilleure idée de ce que la technologie est capable de faire et combien de temps ça va prendre pour le développement.
Jérôme Pasquero
Instabilité des modèles de machine learning.
Si on souhaite effectuer des tests approfondis du modèle avant son déploiement, on risque d’avoir un problème avec les modèles qui s’adaptent continuellement à de nouvelles données, car le modèle continuera à évoluer et on ne disposerait pas d’une version figée que on pourrait tester.
Mrs X
Entraîner les modèles avec plus de données.
On essaie habituellement de montrer le plus de données entrantes possible à l’application pendant la phase d’entraînement, pour essayer de couvrir tous les cas qu’elle risque de rencontrer une fois déployée.
Philippe Bouzaglou
Attention aux cygnes noirs.
De nombreux modèles ML génèrent des résultats dans un espace ouvert (comme les modèles de langage ou les images génératives). Dans ces cas, il peut y avoir des événements extrêmement rares qui pourraient causer un gros problème. Par exemple, générer une image ou un texte pornographique dans une application destinée aux jeunes. Cela empêche l’utilisation de ML dans de nombreux cas ou oblige les développeurs à vraiment contraindre les modèles à des domaines sûrs.
Mrs X
Par rapport à un logiciel traditionnel, il faut tenir compte des risques plus élevés de l’utilisation du machine learning. Une fois dans les mains du public, il peut y avoir des abus ou détournement du produit, et des risques d’atteintes à l’image de la compagnie.
Tester en continu
Il faut reconnaître le manque de maturité du développement en machine learning, tant au niveau des outils, des processus, que des professionnels en intelligence artificielle. D’où l’importance d’apprendre de bonnes pratiques du développement de logiciels traditionnels pour mieux gérer le cycle de vie des produits en machine learning. Ça passe notamment par la mise en place de batteries de tests adaptés et en continu pour s’assurer que les nouvelles données n’engendrent pas de comportements non voulus.
Passer de la théorie de l’école à la pratique de l’industrie.
Les spécialistes en AI sortent tout juste de l’école avec des MS et PHD, qui manquent d’expérience de l’industrie. On doit gagner en maturité pour appliquer un peu plus des techniques de software development au développement de machine learning.
Jérôme Pasquero
Adapter les tests de logiciels traditionnels aux logiciels à base de machine learning.
En programmation traditionnelle on se donne des spécifications, des balises, et on teste notre logiciel en continu pour s’assurer qu’elles soient respectées. En programmation ML on fait ça très peu: on donne un objectif unique, on optimise le système et on utilise le résultat.
Philipe Beaudoin
Tester en continu pour réduire les bugs en continu.
Un logiciel moindrement complexe a une panoplie d’objectifs et de contraintes qui évoluent au fil du temps et de nos apprentissages (lire: des bugs qu’on rencontre ou des comportements imprévus du système). En programmation traditionnelle quand ça arrive on ajoute des tests, on fixe, et ça ne revient plus. En programmation ML on a un peu le bec à l’eau.
Philipe Beaudoin
Gérer le cycle de vie d’un logiciel tout en gérant le cycle de vie des modèles de machine learning.
Le défi est encore plus dur lorsque l’on développe des modèles qui sont spécifiques aux individus, en contraste avec les modèles qui capturent le comportement de groupe. Les modèles individuels dépendent de données granulaires collectées dans des contextes assez complexes, pour inférer des décisions ou des recommandations adaptées aux spécificités des individus. C’est encore plus complexe quand le produit doit s’adapter en temps réel.
Salma Naccache
Limiter la complexité
Complexité des modèles
Il est parfois facile de se dire qu’on va développer un « moonshot » qui va tout régler. Comme pour le développement de produits traditionnels, il est préférable de travailler un produit de ML en itération en associant plusieurs modèles simples, plutôt qu’un gros modèle complexe.
Demande à un data scientist combien de données il a besoin pour son modèle, et il sera incapable de te répondre dès le début du projet.
Éviter de vouloir tout régler avec un modèle très puissant.
On se rend compte qu’on n’a pas assez de données, ou que son modèle est trop compliqué. On essaie d’attaquer des cas de figure extrêmes qui augmentent les besoins en performance, en mémoire, en data pour l’entraînement. Au final, on te ramasse avec un monstre qui n’est plus gérable.
Jérôme Pasquero
Un modèle simple permet d’expliquer plus facilement les résultats.
Si le modèle est très complexe, ce qui est la norme en ML, nous ne pouvons pas retracer la raison pour laquelle une décision a été prise. Il sera difficile de travailler dans certaines applications où les utilisateurs ou la réglementation exigent des explications.
Mrs X
Complexité des équipes
Beaucoup de personnes sont impliquées dans le développement d’un produit de ML (data engineer, data scientist, ML ops, solution architect, backend/frontend developer…). La complexité des projets rend d’autant plus important le rôle de gestionnaire de produit (PM), qui est sensible aux différents enjeux de développement du produit et s’assure d’une bonne communication entre les équipes impliquées.
Communiquer clairement les besoins et les contraintes.
L’équipe ingénierie ML doit s’assurer de produire les modèles, les maintenir, et définir clairement le type, les contraintes et les différents scénarios pour aider l’équipe d’ingénierie logicielle à intégrer les résultats dans le produit final. L’équipe ingénierie ML doit être capable d’abstraire les différents enjeux, afin que l’équipe d’ingénierie logicielle, ainsi que l’équipe produit puissent évaluer quel aspect du produit doit être amélioré ou fixé par une équipe ou l’autre.
Salma Naccache
Faire face au hype
À la fin des années 2000, une compagnie devait absolument avoir une page Facebook. La question de savoir pourquoi et du ROI était souvent secondaire. L’intelligence artificielle vit aujourd’hui le même hype, où les équipes produit ont la pression pour incorporer à tout prix du machine learning.
En ML aussi, le mieux est l’ennemi du bien. Comme pour gestion de produit traditionnel, c’est parfois mieux de commencer à « faker » – de manière manuelle ou semi-automatique, apprendre des premiers usages et ensuite développer les fonctionnalités logicielles.
La première règle du machine learning, est de le faire sans machine learning.
On a la pression pour utiliser du ML, alors qu’on n’a pas encore besoin et qu’on peut simplement hard coder les règles. Le produit est assez efficace sans. Si on n’y arrive vraiment pas sans modèle, c’est là qu’on peut commencer à regarder comment utiliser le ML. Il faut absolument éviter de baser tout ton produit sur un modèle qu’on n’a pas encore développé.
Jérôme Pasquero
La réaction du public peut être imprévisible face à une bête que le monde ne comprend pas vraiment.
L’intelligence artificielle suscite beaucoup d’attention de la part du public. Cela crée à la fois un élan positif pour affirmer qu’il y a de l’IA dans les applications, mais, à l’inverse, beaucoup de craintes, que ce soit de la part des utilisateurs ou des entreprises, qui s’inquiètent d’un « backlash » exagéré dû au battage médiatique associé à l’IA.
Mrs X
Gagner en maturité
Pour finir sur une note optimiste, avec tous les efforts actuels, les pratiques de développement de produit avec du machine learning devraient rapidement gagner en maturité. Compétences, outils et processus de développement spécifiques aux produits en ML devraient à terme amener un standard de qualité similaire au développement de logiciels traditionnels. Dans le prochain article, on verra ensemble quelles sont les compétences clés pour mener à bien le développement d’un produit de machine learning.
En illustration de cette maturité croissante dans le développement de produits avec du machine learning, AskAïa se distingue comme un cas d’étude exemplaire. Utilisant l’IA pour simplifier le parcours d’immigration au Canada, AskAïa démontre comment l’innovation technologique, couplée à une compréhension approfondie des processus complexes, peut aboutir à des solutions efficaces et sécurisées. Ce succès illustre parfaitement la convergence entre l’avancée théorique et l’application pratique dans le domaine de l’intelligence artificielle.
Français / Anglais
- machine learning (ML) = apprentissage machine
- artificial intelligence (AI) = intelligence artificielle (IA)
- data science = science des données
- software development = développement logiciel
- bug = bogue

2 commentaires sur “Comment gérer un produit avec du machine learning”