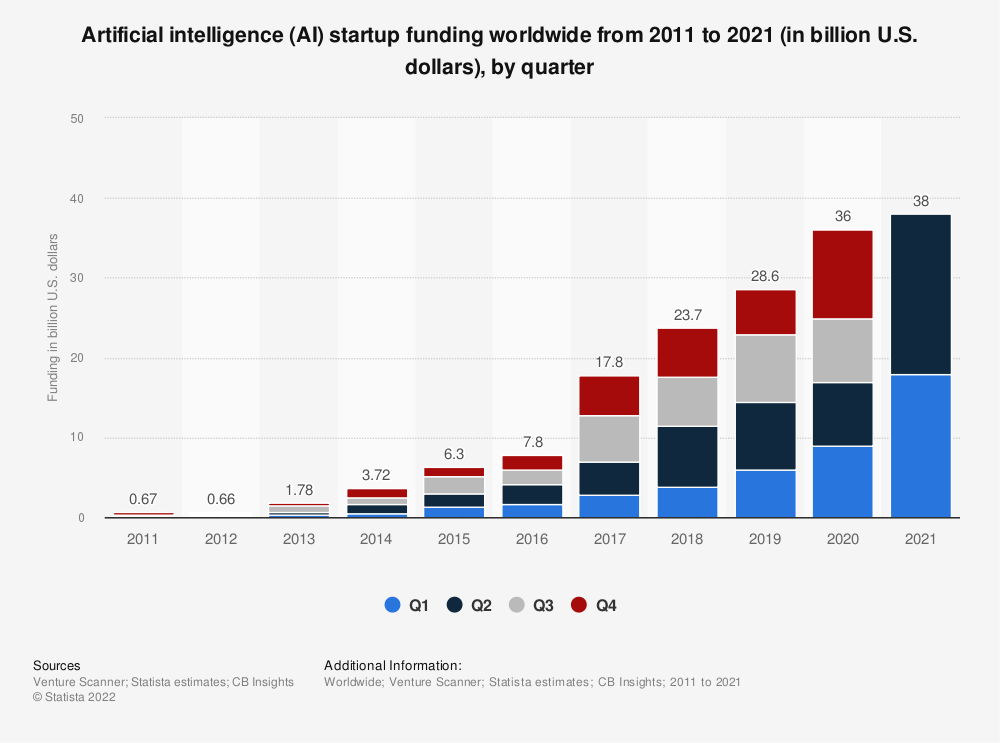
2024 s’annonce électrique dans l’arène de l’intelligence artificielle! OpenAI monte sur le ring, défendant son titre contre une cohorte de géants tech et de challenger. Je me risque à faire 5 prédictions, ou plutôt anticipations, sur le match AI qui va animer nos conversation cette année.
1. OpenAI : l’homme à abattre
OpenAI: toujours leader malgré les turbulences
Le 30 novembre 2022, OpenAI a pris tous les géants de la tech par surprise. En 2024, avec plus de 100 millions d’utilisateurs actif mensuel, 1,3B$ de revenus, et quelques remous à la tête de la compagnie, le statut de pionnier d’OpenAI semble intact. Tout ça me laisse penser qu’il va continuer à leader le marché, à la manière d’Apple pour les smartphones et de Google pour les moteurs de recherche.
La contre-attaque des titans tech
Les géants comme Google et Apple essaient de riposter avec leurs propres innovations. Google intègre à ses services Gemini, son modèle d’IA multimodal avancé, optimisé pour textes, images, audios et vidéos. Pour rattraper son retard, Apple mise gros sur l’IA (+1B$ par an) pour enrichir l’expérience utilisateur sur des appareils clés comme l’iPhone et l’iPad. Meta (Facebook) peaufine LLAMA 3, espérant tailler des croupières à GPT-4. Amazon mise évidemment beaucoup sur l’IA avec AWS (Bedrock, Rekognition, Code Whisper…) et sur Anthropic, avec un investissement de 4B$.
Microsoft et OpenAI: un partenariat gagnante
Avec un investissement de plusieurs milliards de dollars – en cash et en serveur Azure, Microsoft tire son épingle du jeu par son partenariat avec OpenAI, et en intégrant GPT et DALL-E dans son portefeuille de produits. Cette alliance stratégique, n’empêche pas Microsoft de travailler sur ses propres projets d’IA (VALL-E, Phi) et Copilot, sa version maison de ChatGPT qui vient de débarquer sur Android et iPhone.
2. Les défis de l’IA matérielle : OpenAI et Apple
L’aventure périlleuse d’OpenAI dans le hardware
J’adore la philosophie de design de Jony Ive pour les produits Apple – simplicité, l’élégance, la fonctionnalité et l’innovation. Mais même avec lui, OpenAI risque de se heurter aux réalités du développement de matériel, un secteur où la société n’a pas encore fait ses preuves. OpenAI s’est forgé une solide réputation grâce à ses modèles d’IA, mais la conception, la production et la distribution de matériel intelligent sont d’un tout autre ordre.
L’avantage potentiel d’Apple
Même s’il a un an de retard, Apple se positionne avantageusement pour intégrer la puissance de l’IA dans les appareils qu’on utilise tous les jours. La firme de Cupertino est rarement la première à lancer de nouvelles innovations, mais son habileté à fusionner technologie de pointe et interface utilisateur intuitive pourrait donner un produit unique d’intelligence artificielle. La maturité d’Apple en matière d’intégration de l’hardware et du software pourrait lui conférer une longueur d’avance face aux défis auxquels OpenAI pourrait se confronter.
3. La montée de la compétence en prompt AI
La nouvelle littératie technologique
L’année 2024 marque un tournant dans la manière dont nous interagissons avec les machines. La compétence en prompt AI devient aussi essentielle que savoir effectuer une recherche sur Internet. Pour Logan Kilpatrick (OpenAI), la capacité à communiquer clairement avec une IA est devenue prépondérante, déplaçant l’importance de la compétence technique vers l’efficacité de la communication humaine. La maîtrise des prompts AI met en évidence la nécessité de savoir interagir avec les intelligences artificielles par le biais du langage naturel.
Communication critique pour l’interaction AI
Avec la génération de l’IA, les compétences traditionnelles en lecture, écriture et parole restent fondamentales, mais doivent être complétées par la capacité à formuler précisément des demandes à une une machine. La fluidité de la communication humaine-IA devient aussi importante que la capacité à coder ou à analyser des données. Je ne serais pas étonné que cette nouvelle compétence langagière soit enseigné bientôt à l’école.
Formation et adaptabilité: clés de la compétence AI
Alors que l’IA se fraye un chemin dans la prise de décision en entreprise, la curiosité et l’adaptabilité émergent comme des qualités essentielles. Les travailleurs devront se former et comprendre les nuances des outils d’IA pour les utiliser à bon escient et anticiper leurs implications. Les compétences en prompt AI ne seront plus l’apanage de quelques initiés mais vont devenir impératives pour tous, induisant une transformation profonde des perspectives de marché du travail, d’éducation et de formation professionnelle.
4. L’Impact transformateur de l’IA sur le marché du travail
Révolution des rôles et compétences
L’avancée de l’intelligence artificielle va transformer le marché du travail en 2024, pour atteindre un point de basculement majeur. Alors qu’on imaginait des robots remplacer les métiers manuels, ce sont finalement les emplois de cols blancs qui sont le plus touchés. D’après une étude de Pew, près d’un cinquième des travailleurs américains occupent des postes hautement exposés à l’IA, notamment des analystes budget, des spécialistes de la manipulation de données et des développeurs Web. L’IA reconfigurent ces métiers, exigeant non seulement l’automatisation, mais également l’amélioration des capacités analytiques humaines.
Défis et opportunités dans l’automatisation
La Gen AI en particulier présente des défis uniques pour les professions intellectuelles. Une étude de Pearson a découvert que, en Inde, certaines tâches des emplois de cols blancs pourraient être automatisées à un taux de 30 % ou plus, contre moins de 1 % pour les emplois de cols bleus. Des analyses menées par la Harvard Business School et le Boston Consulting Group montrent qu’avec l’utilisation de GPT-4, des consultants ont vu leur productivité s’accroître de façon significative en termes de vitesse et de qualité, bien que pour des problématiques plus complexes, la précision des réponses générées puisse être affectée.
Adaptation et stratégies futures
Pour anticiper les bouleversements induits par l’IA, l’adaptabilité devient donc essentielle. Les professionnels vont devoir se tourner vers la formation continue et le développement de compétences qui sont en synergie avec l’IA — comme la pensée critique et la résolution de problèmes. Les entreprises, de leur côté, peuvent s’appuyer sur l’IA pour non seulement automatiser les fonctions routinières, mais également optimiser la prise de décisions stratégiques. C’est l’opportunité pour les travailleurs d’investir dans des tâches à plus forte valeur ajoutée et cultiver des compétences intrinsèquement humaines.
5. L’ascension des mini-modèles d’IA
Un futur redéfini par les mini-modèles
En 2024, l’ascension des mini-modèles d’IA annonce un changement de paradigme dans le monde de l’intelligence artificielle. Après l’ère des colosses comme GPT-4, avec ses 1,7 trillion de paramètres, l’attention se tourne vers des solutions plus petites, agiles et économiques. Ces modèles compacts, avec des capacités allant de 2,7 à 3 milliards de paramètres pour des entités comme Phi-2 de Microsoft et Dolly v2-3b de Databricks, respectivement, offrent des avantages incontestables: une empreinte écologique réduite, une intégration dans des dispositifs variés, et une spécialisation accrue.
Personnalisation à la portée de la main
Imaginez un futur où chaque smartphone et objet connecté héberge un mini-modèle d’IA personnalisé, capable de s’adapter et de se spécialiser selon les besoins et les habitudes de son utilisateur. Ces assistants AI ultra-personnalisés pourraient gérer des tâches variées, allant de la gestion de l’emploi du temps à des recommandations sur mesure, en passant par l’analyse de données de santé, offrant ainsi une expérience utilisateur hyper individualisée et intuitive.
Révolution dans le monde professionnel
Dans le domaine professionnel, les mini-modèles d’IA se profilent comme les nouveaux artisans de la productivité et de l’innovation. Chaque métier, chaque tâche en entreprise pourrait bénéficier de son propre modèle AI spécialisé, conçu pour optimiser les processus, faciliter la prise de décision, et stimuler la créativité. Des modèles d’IA dédiés pourraient transformer des secteurs entiers, des ingénieurs utilisant des modèles spécialisés dans l’optimisation de la conception, aux médecins s’appuyant sur des AI pour des diagnostics plus précis.